ひらがな表示がうまいこといったので「わ~い!」とばかりに、漢字表示にも挑戦しました!
ひらがな表示の時は、フォントデータをそのままソース内に書いてました。
fontDataDict = {
"ぁ":[0x0000,0x0000,0x0000,0x0000,0x0400,0x3F80,0x0800,0x0F00,0x1A80,0x2A80,0x2C80,0x1900,0x0000],
"あ":[0x0000,0x0400,0x04C0,0x7F00,0x0800,0x0F80,0x1940,0x2920,0x4A20,0x4C20,0x3440,0x0180,0x0000],
"ぃ":[0x0000,0x0000,0x0000,0x0000,0x0000,0x2100,0x2100,0x2080,0x2080,0x2480,0x1800,0x0000,0x0000],
"い":[0x0000,0x0000,0x0000,0x2000,0x2080,0x4040,0x4040,0x4020,0x4220,0x2400,0x1800,0x0000,0x0000],
"う":[0x0000,0x0000,0x0000,0x2000,0x2080,0x4040,0x4040,0x4020,0x4220,0x2400,0x1800,0x0000,0x0000],
(このまま「ん」まで続く)
漢字も同じようにやればいいや、と思ったんですが、さすがに量が多いので手作業の変換は無理。フォントデータから上の形式に変換するPythonスクリプトを作って、PCでソースを生成することにしました。
キモとなる部分は、JISコード→文字への変換でした。
フォントデータファイル「mplus_j12r.bdf」で、「あ」は「0x2422」です。該当箇所は、こういうデータでした。
STARTCHAR 0x2422 ENCODING 9250 SWIDTH 886 0 DWIDTH 12 0 BBX 12 13 0 -2 BITMAP 0000 0400 04C0 7F00 0800 0F80 1940 2920 4A20 4C20 3440 0180 0000 ENDCHAR
ここでのSTARCHAR 0x2422が文字コードになります。
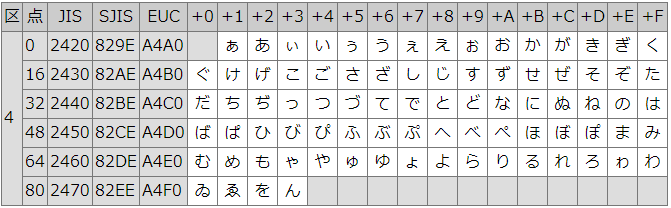
「あ」の0x2422は、JISコードですね。
import binascii
fontCode = line[12:16]
try:
fontChar = binascii.unhexlify("1b2442" + fontCode).decode('iso-2022-jp')
except:
#コードから変換できなかった文字は読み飛ばし
Pythonでの変換はこれでいけました。「0x」を取り、「漢字in」のシフトコード「1b2422」を追加して「iso-2022-jp」として変換です。
文字に変換できれば、あとは並べて整形して出力するだけ。変換可能だったのは6879文字。6879行のソースコードができました。
半角英数字まで考慮するのであれば、フォントファイルのSWIDTH / DWIDTH / BBX あたりの指定も見てあげないといけないと思うのですが、「日本語全角だけ」で考えれば、BITMAP部分だけ見れば良さそうです。ここは割りきりで。
これを、M5Cloudに貼り付けようとしたのですが…貼り付けた後、セーブできない。ソースコード量の上限があるみたいです。であればと、そのままソースをアップロードしてみました。しかしながら、再起動後に、M5Stackは起動画面で停止…。どうやら、メモリ不足らしいです。さすがにソースコードに全文字データを保持するのは、富豪プログラミングすぎたのか。
メモリ不足であると思われることと、変換がうまく行ってることだけ確認するために、数文字だけ貼り付けてみたところ動きました。

データの扱いは間違っていないのでよかった。
次のアプローチ。対応する文字数を減らそうかなあと思ったんですが、英数字+ひらがな+かたかな+数十文字ていどしか無理そう。メモリに読み込むのに無理があるんですね。
Pythonのファイル処理のあたりのコマンドを見てますと、seekコマンドでランダムアクセスできることを知りました。フォントファイル内で、アクセスする位置がわかれば、直接そこから読み込むことが可能なのですね。これならフォントデータをファイル上に置いておいてもそんなに遅く無さそう。フォントファイルは1文字26バイトなので、これをそのままバイナリデータとして書き出しておきます。フォントファイル上の何文字目かがわかれば、26 x(文字位置)から26バイトを取得すればいいのです。一取得のためのインデックス一覧だけ作って、ソースファイルに入れておくことにします。こういう感じ。
self.fontIndexData=[ " ","、","。",",",".","・",":",";","?","!", "゛","゜","´","`","¨","^"," ̄","_","ヽ","ヾ", (6879文字、最後まで続く)
これでも…やっぱり動かない。まだまだメモリ不足の様子。インデックス文字数をドンドン減らしていくと、動くようになったのですが、これでも対応できたのは、英数字+ひらがな+かたかな+数十文字ていどでした。まあ、インデックス→バイナリデータ読み込みが確認できたので、それはそれで得るものはあった。
次は、インデックスファイルをソースに直接読むのではなくて、外部ファイル読み込みにしてみました。
このあたりでシリアルモニタの存在を知りました!
見てみると、やはり、インデックス読み込み中にメモリ不足発見。対象の文字を減らすと読み込み完了、正常に動作することも確認。数百字程度までだ…。
何とも手詰まり感。
ここで、しばらく停滞していたのですが、思いつきました!
MicroPython内部の文字コードは、Unicode / UTF-16BE のようです。日本語の部分だけなら、0~65535に収まる範囲。であれば、このさい、UTF-16BE→フォント並び順へ、直接変換できるバイナリインデックスファイルを作ってしまえばいいのでは?フォント並びは2バイトあれば足りるので、65535 x 2 でたかだか128KBですし!これだ!

こういう感じだ!
これに用いるデータを作成するためのPythonスクリプトを書きました。
ここでのポイントは、文字のUTF-16BEコードを取得すること。
ord("あ")
これでいけます。JIS→UTF-16BEのめんどくさい文字コード変換は、ぜんぶPythonに投げちゃうことができました。作ったPythonファイルがこちら。PCで動かします。引数でフォントファイル名を渡すと、以下のファイルを生成します。
fontData.bin:バイナリ化したフォントデータ fontIndex.txt:フォント一覧。インデックスをソースに描こうとしてた名残 fontCode.csv:フォント並びのインデックスをテキスト出力。目視確認用。 fontCode.bin:バイナリ化したフォント並びのインデックス
実際のプログラムで使うのは、fontData.binとfontCode.binだけです。
引数でフォント名与えられますけれど、ハードコーディング的に「M+ BITMAP FONTS」の「mplus_j12r.bdf」に合わせてるところあるので、他のフォントだとうまく動かないかも。
M+ BITMAP FONTS
http://mplus-fonts.osdn.jp/mplus-bitmap-fonts/
fontConverterBin.py
import sys
import binascii
args = sys.argv
fileName = args[1]
fontFile = open(fileName, 'r')
fontBinaryFile = open("fontData.bin", 'wb')
fontIndexFile = open("fontIndex.txt", 'w')
fontCodeFile = open("fontCode.csv", 'w')
fontCodeFileBin = open("fontCode.bin", 'wb')
fontChar = ""
fontCode = ""
fontDataCount = 0
findBitmap = False
fontBitmap = bytearray([])
fontOrderHash = {} #キー:Unicode 値:フォントファイルでのOffset
index = 0;
for line in fontFile:
#フォントデータ読み込みモードの場合、13行読み込む。13行読み込み完了時にソース出力
if fontDataCount > 0:
fontLineData = int("0x" + line[:-1], 0)
hData = int(fontLineData >> 8) #上位バイト
lData = fontLineData & 0x00FF #下位バイト
fontBitmap.append(hData)
fontBitmap.append(lData)
fontDataCount = fontDataCount + 1
if fontDataCount > 13:
fontBinaryFile.write(fontBitmap)
fontDataCount = 0
fontCodeFile.write(str(index - 1) + "," + fontChar + "," + fontCode + "," + hex(ord(fontChar)) + "," + str(ord(fontChar)) + "\r")
#STARTCHARが来たらJISコードで文字に変換して保持
if line.find("STARTCHAR") != -1:
fontCode = line[12:16]
try:
fontChar = binascii.unhexlify("1b2442" + fontCode).decode('iso-2022-jp')
fontOrderHash[ord(fontChar)] = index
findBitmap = True #次に見つけたBITMAPをフォントデータとして取り込む
fontIndexFile.write('"' + fontChar + '",')
index = index + 1
if index % 10 == 0:
fontIndexFile.write('\r')
except:
#print("#" + fontCode + ":変換不可")
fontChar = ""
continue
#BITMAPが来たらそこから13行がフォントデータ
if line.find("BITMAP") != -1:
if findBitmap == True:
fontBitmap = bytearray([])
fontDataCount = 1
findBitmap = False
for fontOrder in range(1,65535):
if fontOrderHash.get(fontOrder):
fontOffset = fontOrderHash[fontOrder]
else:
fontOffset = 0
fontOffsetBin = bytearray([])
hData = int(fontOffset >> 8) #上位バイト
lData = fontOffset & 0x00FF #下位バイト
fontOffsetBin.append(hData)
fontOffsetBin.append(lData)
fontCodeFileBin.write(fontOffsetBin)
fontFile.close()
fontBinaryFile.close()
fontIndexFile.close()
fontCodeFile.close()
fontCodeFileBin.close()