ひらがなの表示ができるようになったので、なにかニュースヘッドラインのようなものを表示させたいです。
ニュースの情報は漢字混じりなので、最初にこれをひらがなだけの文章に変換する必要があります。
探してみると、docomo Developer support から「ひらがな変換API」が提供されていました。使用するにはAPIキーが必要なのですが、ユーザ登録すれば、無料で使用可能とのことです。これ使ってみます。
docomo Developer support:API/ツール API 言語解析
https://dev.smt.docomo.ne.jp/?p=docs.api.page&api_name=language_analysis&p_name=api_4
もともとは、Gooで提供されているサービスですね。こちらは、GitHubアカウントの登録が必要になってます。
gooラボ API ひらがな化API
https://labs.goo.ne.jp/api/jp/hiragana-translation/
MicroPythonから、ひらがな変換APIは、こういう感じで呼び出せます。
import urequests
import ujson
import json
API_KEY = "[取得したAPIキー]"
#ひらがな変換
headers = {'content-type': 'application/json'}
requestURL = 'https://api.apigw.smt.docomo.ne.jp/gooLanguageAnalysis/v1/hiragana?APIKEY=' + API_KEY
requestObj = {"request_id":"record001", "sentence":”変換するテキスト", "output_type":"hiragana"}
requestJson = json.dumps(requestObj).encode("utf-8")
hiraResponse = urequests.post(requestURL, headers=headers, data=requestJson)
hiraJson=ujson.loads(hiraResponse.text)
hiraText = hiraJson["converted"]
urequestsでのhttp処理は、こちらのサイトを参考にさせていただきました。
MicroPythonでurequestsを使う
http://blog.boochow.com/article/454341667.html
表示元となるデータは、Yahooのヘッドラインから取ってくることにします。
Yahooニュースヘッドライン一覧
https://headlines.yahoo.co.jp/rss/list
表示させるのは、ITヘッドラインにしましょう。
Yahoo!ニュース・トピックス – IT
https://news.yahoo.co.jp/pickup/computer/rss.xml
ニュースサイトのヘッドラインは、まだまだXMLばっかりですね。JSONで取れるようになっていればいいのに…。
XML→JSONへの変換をしたいので、そういうWebサービスが無いかと探してみました。
以前は、そういうWebAPIが有名どころからもサービスされてたようなのですが、最近はそういうのは、ツール側のライブラリがサポートしてるみたいですね。
残念ながら、MicroPythonにはそういうのは無さそう。
目的としては、XML→JSONの変換ではなくて、XMLの中から必要な文字列を取得することなので、強引にスクレイピングで行ってみましょう。
取得したXMLはこういう感じです。
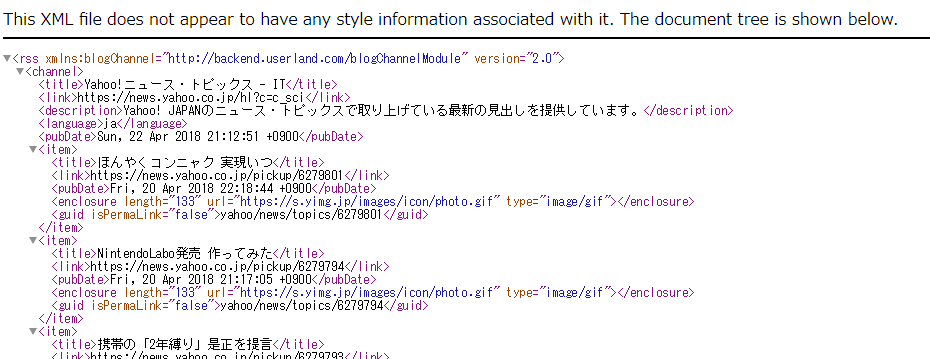
上から読んでいって、最初に出てきた<item>の次の<title>~</title>の間を取得できれば良さそうです。
#Yahooヘッドライン取得(XML)
yahooHeadLineResponse = urequests.get('https://news.yahoo.co.jp/pickup/computer/rss.xml')
yahooHeadLine = yahooHeadLineResponse.text
#<item>が出るまで読み飛ばし
#次の行の<title></title>の間がニュースタイトル
itemIndex = yahooHeadLine.find("<item>")
#itemIndex以降で最初に出てくる<title>と</title>の間を取得
yahooHeadLine = yahooHeadLine[itemIndex:-1]
titleStartIndex = yahooHeadLine.find("<title>") + 7 #<title>の分をずらす
titleEndIndex = yahooHeadLine.find("</title>")
titleText = yahooHeadLine[titleStartIndex:titleEndIndex]
少々強引でも取得できればOK!後は、これで取得した文字列を、ひらがな変換して、1行13文字で画面表示します。全体はこうなりました。(こっちで作ったjpfontもimport)
from m5stack import lcd
import urequests
import ujson
import json
import jpfont
API_KEY = "[取得したAPIキー]"
#Yahooヘッドライン取得(XML)
yahooHeadLineResponse = urequests.get('https://news.yahoo.co.jp/pickup/computer/rss.xml')
yahooHeadLine = yahooHeadLineResponse.text
#<item>が出るまで読み飛ばし
#次の行の<title></title>の間がニュースタイトル
itemIndex = yahooHeadLine.find("<item>")
#itemIndex以降で最初に出てくる<title>と</title>の間を取得
yahooHeadLine = yahooHeadLine[itemIndex:-1]
titleStartIndex = yahooHeadLine.find("<title>") + 7 #<title>の分をずらす
titleEndIndex = yahooHeadLine.find("</title>")
titleText = yahooHeadLine[titleStartIndex:titleEndIndex]
#ひらがなに変換して出力
headers = {'content-type': 'application/json'}
requestURL = 'https://api.apigw.smt.docomo.ne.jp/gooLanguageAnalysis/v1/hiragana?APIKEY=' + API_KEY
requestObj = {"request_id":"record001", "sentence":titleText, "output_type":"hiragana"}
requestJson = json.dumps(requestObj).encode("utf-8")
hiraResponse = urequests.post(requestURL, headers=headers, data=requestJson)
hiraJson=ujson.loads(hiraResponse.text)
hiraTitle = hiraJson["converted"]
#1行13文字で画面表示
lcd.clear()
lcd.setCursor(0, 0)
lcd.setColor(lcd.WHITE)
rowCount = int(len(hiraTitle) / 13) + 1;
for rowIndex in range(rowCount):
rowTitle = hiraTitle[13 * rowIndex:13 * rowIndex + 13]
jpfont.printString(rowTitle, 0, rowIndex * 12)
実行!

わーい、出たー!
後は、複数情報の表示、定期的な読み直し、ボタンによるトピックジャンル切り替え、などができたらよさそうです!