いろいろなコンテンツの一部分を切り抜いて保存できるというスクラップブック機能。
僕は普段WebブラウザはChrome使ってるので、Chromeで試してみました。

取り込み元のWebページをChromeで表示。スクラップ機能を起動して、一部分をペンで囲んで…
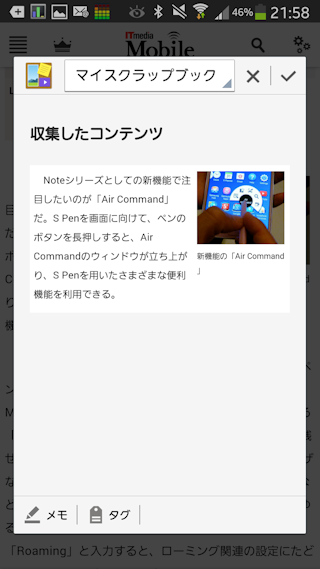

取り込みました。でもこれ、単なる画像なんですよね。画面ハードコピーして画像クリッピングされた感じ。取り込み元のURLもわからない。これじゃ、再利用できないし、元ソースも辿れないし、スクラップしてもあんまり意味ないですよね。
さすがに、これは変だと思って、標準ブラウザで同じようにやってみました。すると…
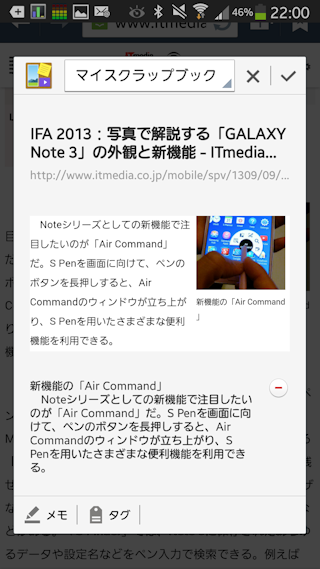
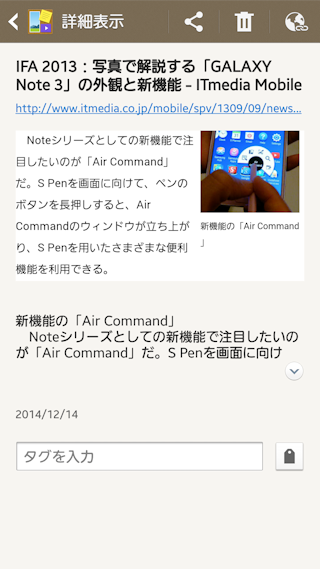
おお!ページタイトルも元URLも取りこまれている!さらに本文もテキストデータで取り込まれている!何!この違い!
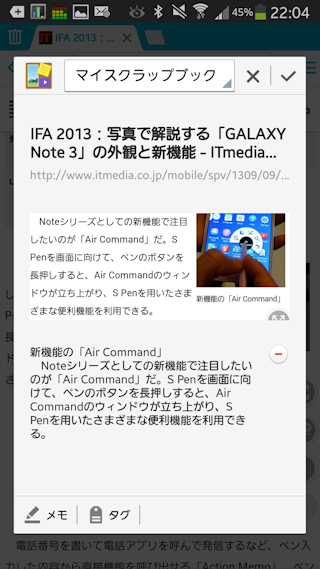
他のブラウザでも試してみたところ、Boat Browserでも可能でした。スクラップブックを使っていくのであれば、Chromeは、やめといた方が良さそうですね。

カテゴリ: 通信
Google Playで詳細を見る

カテゴリ: 通信
Google Playで詳細を見る
ブラウザ以外のアプリでもスクラップ可能です。アプリごとに取得できる情報は違うので、使う前にどんなデータが取得されるのか、試してみないといけないですね。
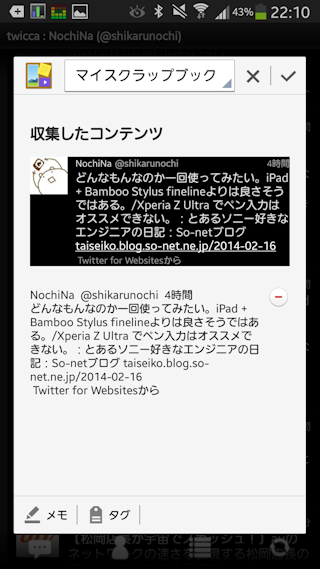
Twitterクライアントtwiccaからの取り込みはこんな感じ。Tweet URLが取得できればよかったのだけどなー。

カテゴリ: ソーシャルネットワーク
Google Playで詳細を見る
文字が取得できないアプリで、何とかして文字を取得したい!という場合はOCRアプリを使うのが良さそうです。

カテゴリ: ツール
Google Playで詳細を見る
起動後、メニューのSetting – Manage Languages から、日本語データをダウンロードしておきます。
スクラップブックアプリ、対象を選び、シェアボタンを押して「映像+テキスト」を選択、アプリで「OCR Instantly Free」を選択。
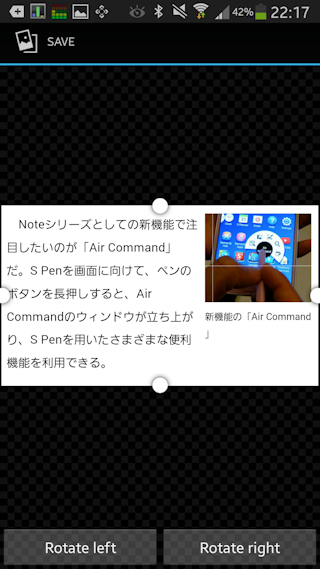
読み取り範囲を選択。
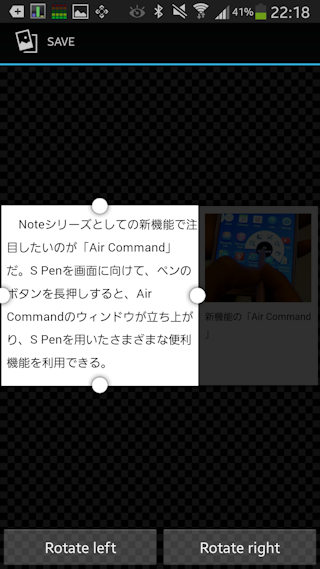
選択したら SAVE。「Japanese」を選択して「OCR!」ボタンを押すと、解析開始します。
その結果は…
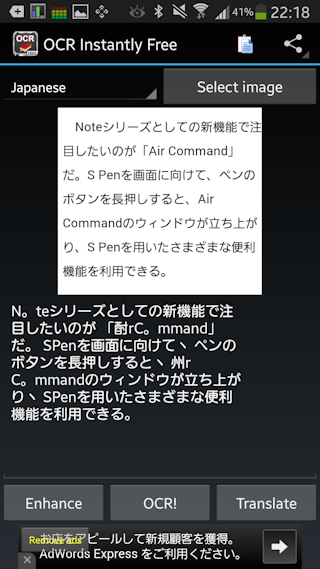
日本語の部分はいい感じですね。(読点が微妙ですが。)
基本は日本語として読んでるので、英単語の部分は厳しい。
PRO版(589円)であれば、「Multi-language OCR – Perform OCR with multiple languages.」なのでマルチランゲージでも大丈夫だと思います。上の日本語の結果からして、期待して良さそう。このアプリは、本を写真に撮ってそれをOCRできるほどの性能があるので、WebページのハードコピーOCRなんか楽勝なのでしょう。

カテゴリ: ツール
Google Playで詳細を見る
で、結局、このスクラップブックという機能をどうやって使っていくのがいいか、まだわかってないです。サムネイル付のWebブックマークだと思えばいいのかな?